
If you don’t know what DBT is just unravel the acronym and you will have a good understanding of it, Data Build Tool.
DBT focusses on the transformation part within ETL, and it combines a host of best practises and tools from Data and Software Engineering.
Without going into to much detail what DBT is and where it is used, I would rather like to focus this article on the productionalization component of DBT. DBT is amazing and really works great when running from your local machine, but how should this look like in a production environment. This article will show you how to run DBT in a docker container, how and where you run your container is up to you.
First you will need to create a profile.yml file in your project directory. We will inject the profile.yml file when executing the DBT commands. Because DBT will by default search for your profile.yml file in your ~/.dbt folder, which we won’t have in the container.
project_name:
target: dev
outputs:
dev:
type: bigquery
project: project_id
dataset: dataset_name_dev
location: EU
priority: interactive
threads: 10
timeout_seconds: 300
fixed_retries: 1
method: service-account
keyfile: '/service_account_key.json'
prod:
type: bigquery
project: project_id
dataset: dataset_name_prod
location: EU
priority: interactive
threads: 10
timeout_seconds: 300
fixed_retries: 1
method: service-account
keyfile: '/service_account_key.json'
Next step, lets create the dockerfile in your project directory
FROM fishtownanalytics/dbt:1.0.0
WORKDIR /project_name
COPY entrypoint.sh ./
COPY . ./
ENTRYPOINT "./entrypoint.sh"Docker file breakdown:
- We will be pulling the Fishtown analytics docker image as provided by them on Docker Hub
- Create a working directory for the project
- Copy our entrypoint.sh file into the root directory
- Then we load the project folder into the container, which contains all our models
- Define the entrypoint of the container. In this case, because we have multiple DBT commands we would like to execute, we need to invoke it via a shell script
Note: When defining the image to pull, specify the version to use. The latest tag gives and error
You will notice that we have specified an entrypoint parameter for the dockerfile, this will invoke a shell script to execute the dbt commands we need for our project. Because we have multiple DBT commands we would like to execute in a specific order, we need to invoke it via a shell script
#!/bin/sh
dbt clean --profiles-dir .
dbt deps --profiles-dir .
dbt debug --target dev --profiles-dir .
dbt debug --target prod --profiles-dir .
dbt run --target prod --profiles-dir .
dbt test --target prod --profiles-dir .We will execute the following commands to ensure our project is ready for execution:
- clean - We will clean the target directory to ensure we compile new sql scripts
- deps - Install all dependencies needed for the project, as specified in the packages.yml file
- debug - An utility function to show debug information, for debugging purposes.
- run - Executes compiled sql model files against the current target database
- test - Runs tests defined on models, sources, snapshots, and seeds
We always pass the –profiles-dir flag referring to the working directory we set in the dockerfile. This will instruct DBT to search for the profiles.yml file in the working directory and not in ~/.dbt
We also specify the target directory, because we would like to override the default target set in the profiles.yml file. If you set the target to prod in the profiles.yml file, the target field will not need to be passed for prod intended runs
For a full list of all DBT commands please refer to their documentation DBT Commands
Your project directory should look like this
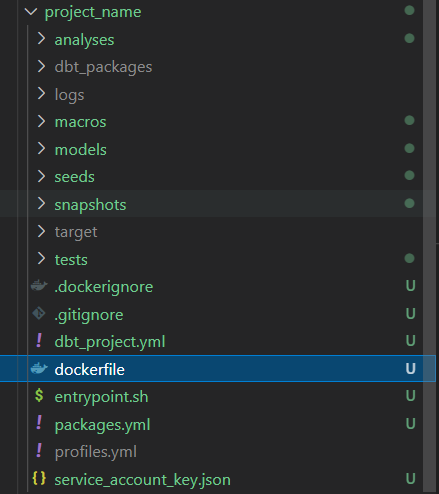
Then we can build the docker image
docker build -t dbt_project_name:latestAnd or run the container
docker run dbt_project_name:latestHappy data transformations, you analytics engineer you!