
Get custom Jira data fields with Azure Data Factory using the Jira connector
-
date_range 08/03/2022 11:50 info
Moving Jira data into a data warehouse is not difficult task for both cloud or on-prem deployments, but what about a heavily customized Jira instances?
Atlassian gives their users the option to customize their own Jira deployment according to their own business needs. So as you can imagine a number of interesting Jira instances can be concocted by businesses. This in turn leads to inconsistent and non standard fields and tables being injected into the application.
Luckily, Jira contains most of the customisations to a single table in the postgress database and they follow the same data flow as standard Jira components :)
But, should we be accessing the database directly of such a configurable system in the first place?
Applications that provides such a level of flexibility to their consumers tend to have a strange denormalized database schemas that forces a normalized view through the applications logic layer. Trying to reverse engineer the application logic from the database up for a data warehouse is always a tough ask. Surely Jira provide an easier why to interact and obtain data from Jira?
Enter the standard Azure Data Factory Jira connector. The connector is a wrapper for the Jira API to access all Jira data without having to deal with the complexities of the database schema. Without the ADF Jira connector, a postgress connector should be used to connect directly to the database. Besides the complexity of reverse engineering the database schemas, with this approach you will also only be able to access on-prem Jira and not Jira Cloud.
Lets get started, first create a new linked service for Jira on ADF, by searching for Jira in the linked services

Setup the connection details to the Jira instance
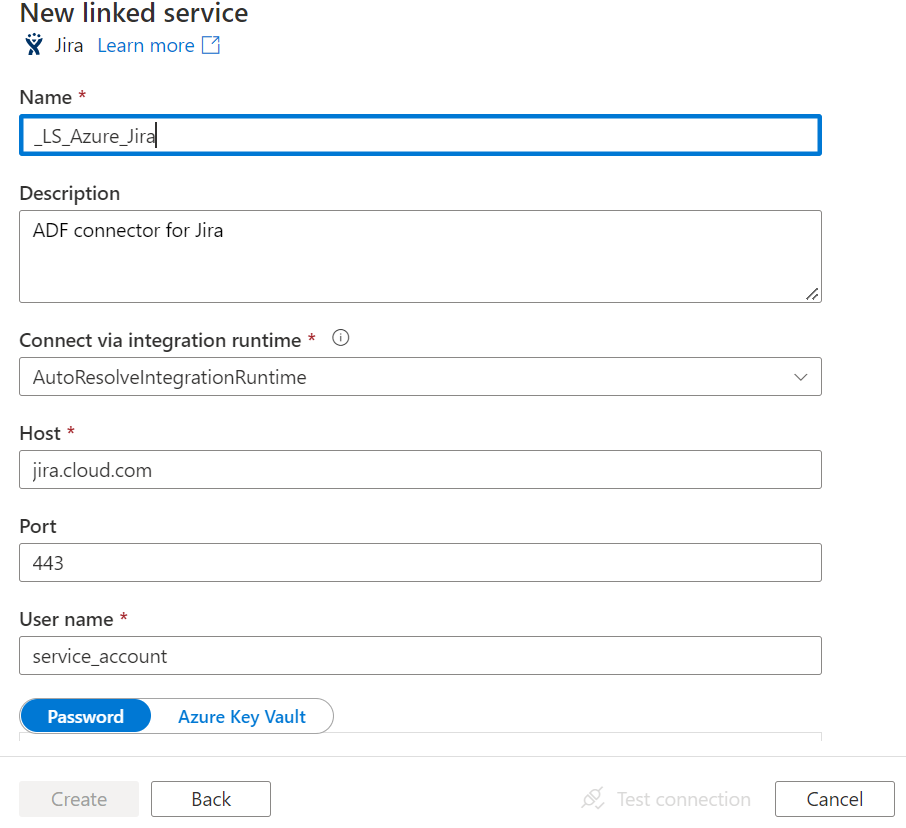
Test your connection to ensure successful connection

Next step will be to create a dynamic data source to act as the sink during the data copy activity. Follow this link if you want to read more about dynamic datasets in ADF
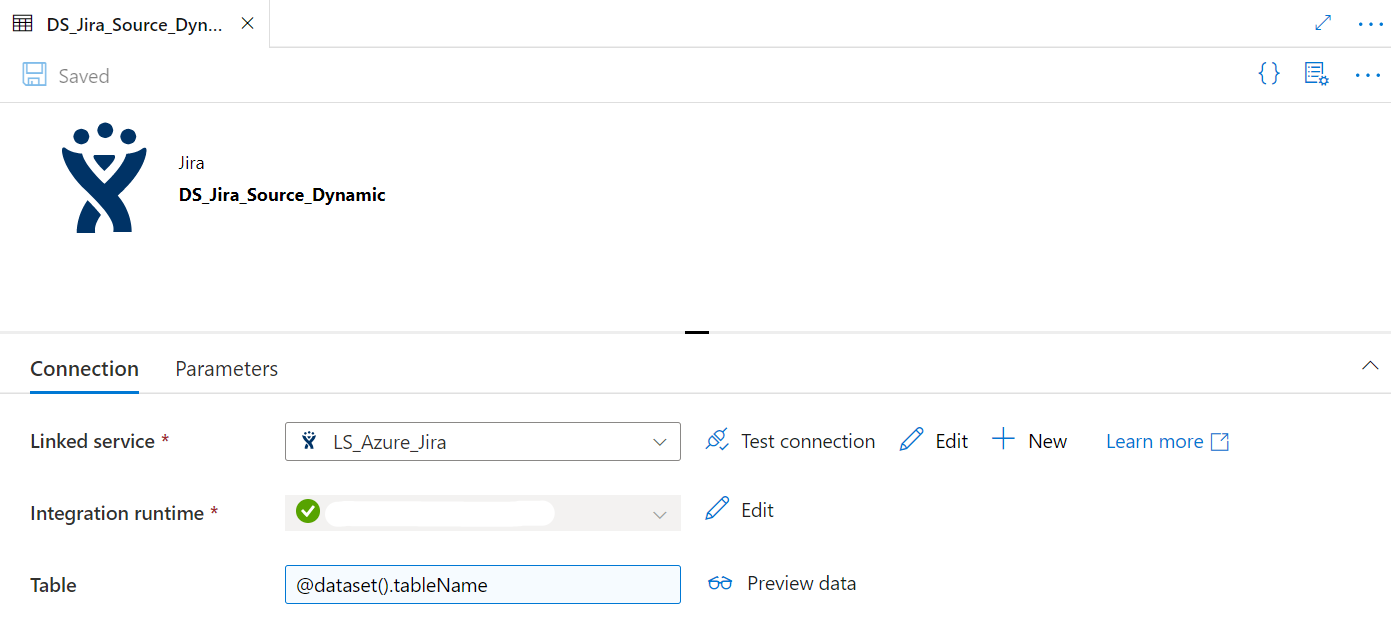

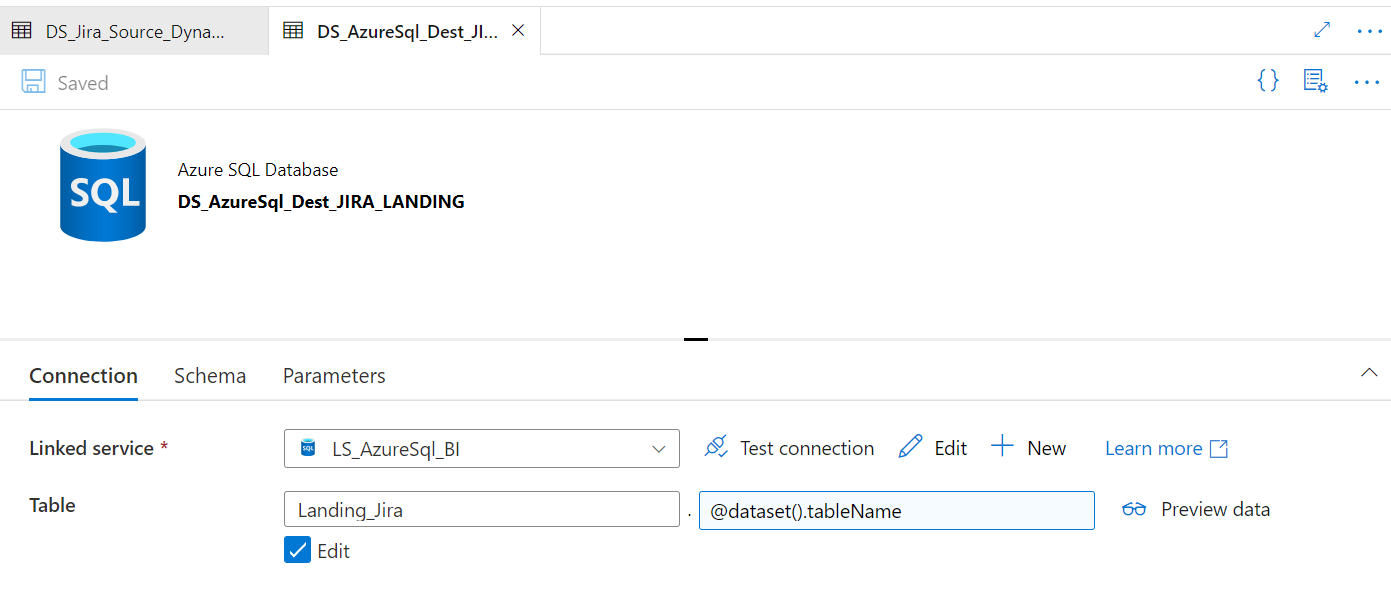
In this scenario we will write to a sql server database also through dynamic datasets in ADF

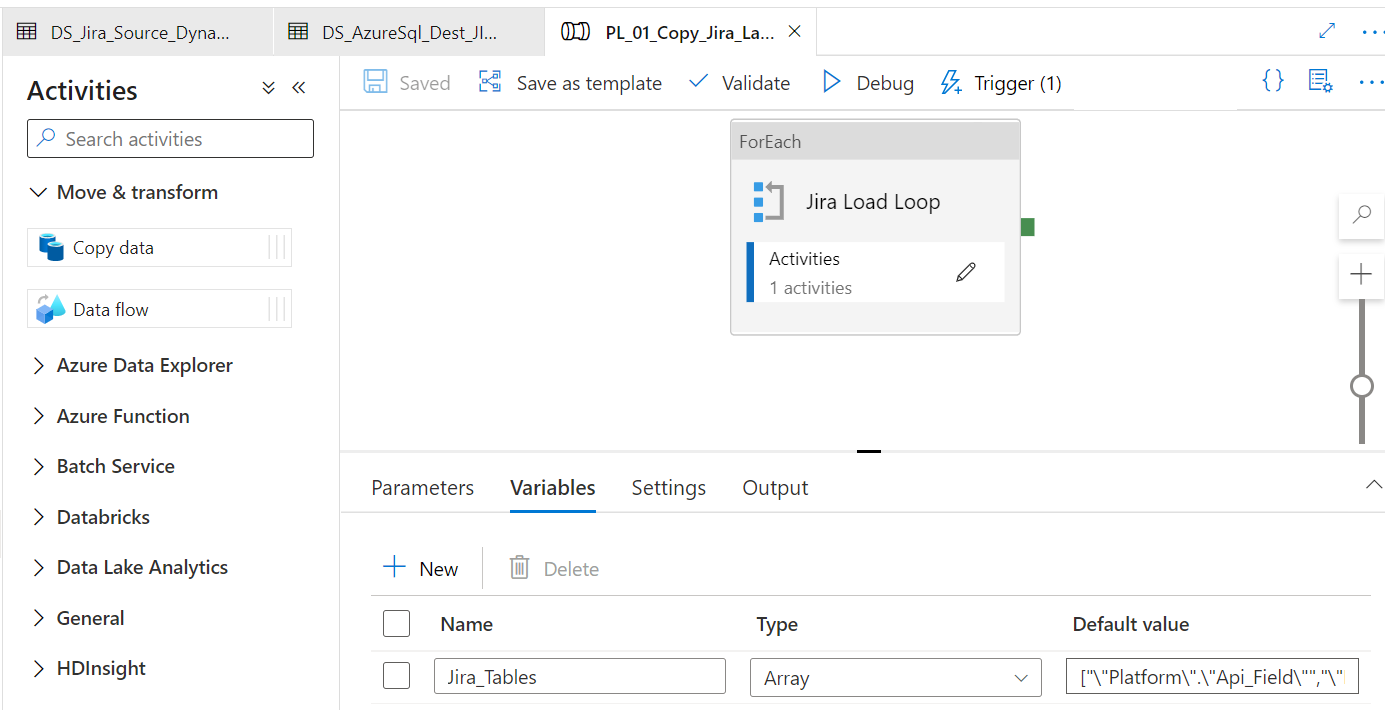
Because of the dynamic setup of our datasets, we can build a pipeline with the ForEach iterator. We will then define the tables we want from the Jira connector with an array setup as a parameters.
I found the following entities to be the core entities needed to extract basic data from Jira:
- “Platform”.”Api_Field”
- “Platform”.”Api_Project”
- “Platform”.”Api_Issue”
- “Extra”.”Api_Issue”
There are plenty more entities to select from, dependent on you requirement
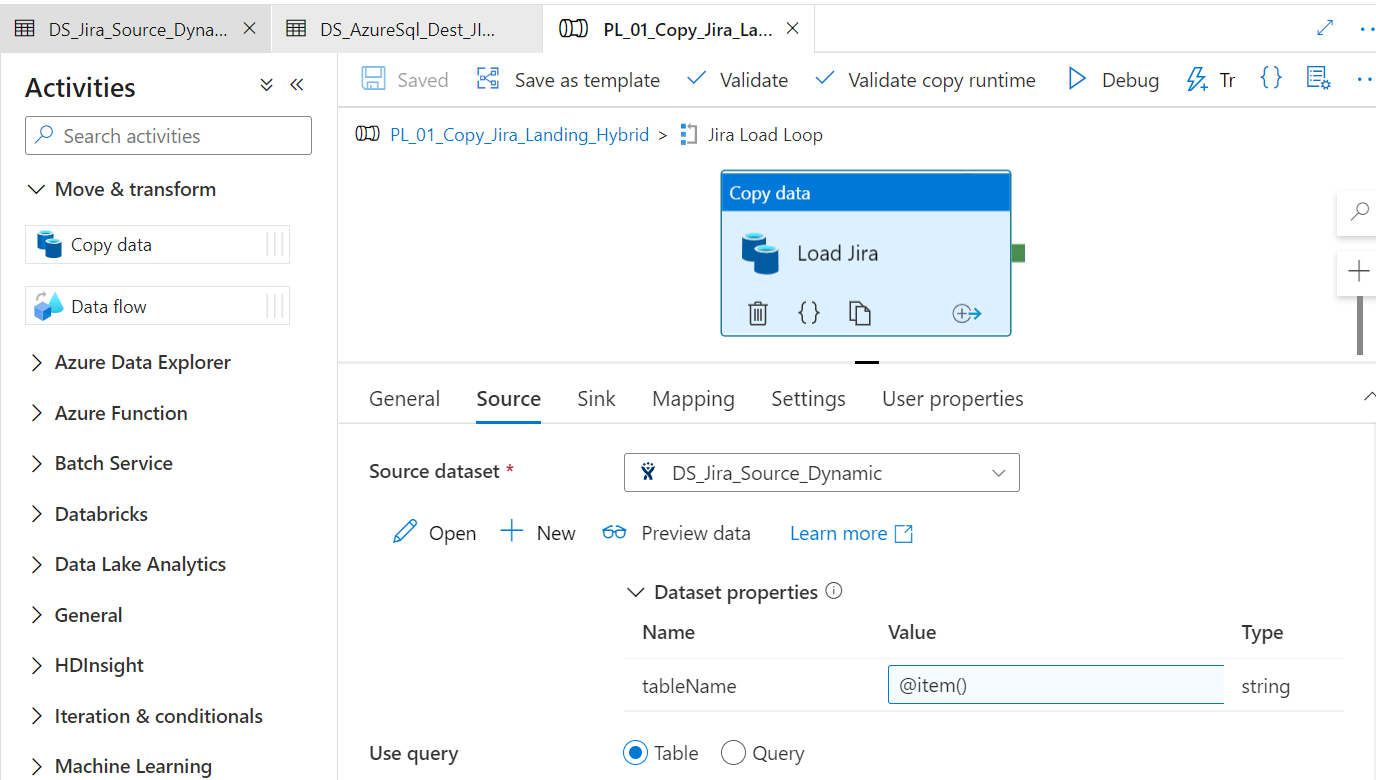
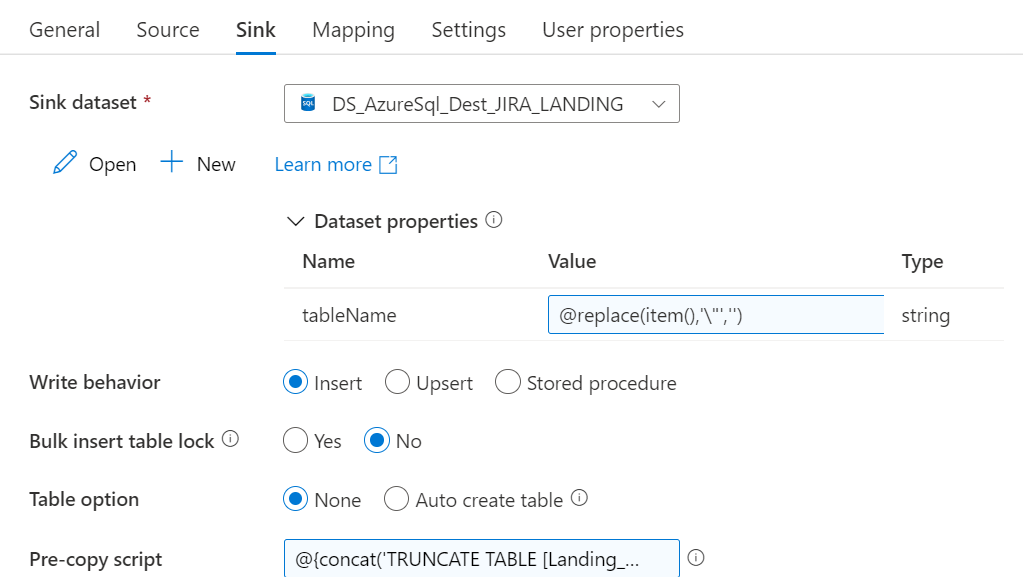
Once the data is available a basic view can be built to mimic the data on the front end
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE OR ALTER VIEW [schema].[uwvStageBusinessReport] AS
SELECT iss.Issue_key,
iss.Fields_Summary as [Description],
issue.Fields_Created as [Date Created],
issue.Fields_Status_Name as [Status],
issue.Fields_Issue_Type_Name as [Type],
-- json fields
JSON_VALUE(customfield_14869, '$.value') as [CustomField1], -- Other type like dropdown value will be accessible by parsing the JSON
-- columns
customfield_14406 as [CustomField1] -- Free text custom fields will be accessible through the column name
FROM [Landing_Jira].["Extra"."Api_Issue"] iss
INNER JOIN [Landing_Jira].["Platform"."Api_Issue"]) issue
ON issue.Issue_Key = iss.Issue_key
WHERE iss.Fields_Project_Key = 'xxxx' -- Business Process Project Key in Jira