
Scrape Data from a Website
-
date_range 17/04/2020 12:35 infosortScrapinglabelPythonBeautifulSoupHTMLScraping
Have you ever had a need to get data from a static website? Or, do you find yourself going to websites to check the status or price of something on regular intervals?
Why not use web scraping to obtain that information for you and store the results in a useful and reusable format like a text file, csv or excel?
During this tutorial we will look at the basics of extracting data from a static website. We will be scraping country`s GDP figures from Wikipedia and store it in a plain text file.
Tutorial Overview
In this tutorial we will discuss the following:
- What are the differences between web crawling and web scraping?
- Are you allowed to scrape data from any website?
- Basic HTML
- BeautifulSoup
- How to approach scraping
- How to use BeautifulSoup to scrape a website
What are the differences between web crawling and web scraping?
You might have heard web crawling and web scraping being used interchangeably. So, what is the difference?
- Web crawling the act of automatically downloading a web page’s data, extracting the hyperlinks it contains and following them. The downloaded data is generally stored in an index or a database to make it easily searchable. Probably the best-known crawler bot is the Googlebot
- Web scraping the act of automatically downloading a web page’s data and extracting very specific information from it. The extracted information can be stored pretty much anywhere (database, file, etc.).
Both activities are similar and share several attributes but are used to achieve 2 different objectives. In our case, we are only going to scrape data. We will only be accessing a single page to obtain a specific dataset, from an html page.
Are you allowed to scrape data from any website?
The activity of web scraping is not illegal, and any site can be scraped. As publicly available data would be sent to your computer, in the same way that it would have, if you had no intention of scraping it.
The problem however arises when the data is obtained in a way which violates the websites term and conditions (T&C). If the website explicitly states in its T&C’s that the site cannot be scraped, then it would become illegal to do. If you just take a second and think about it, it is as good as you are plugging your house into your neighbours and drawing electricity on his account, without his permission obviously When scraping a website a request is made to a server, that server in return needs to process your request and serve your with a result. So, in this case you used the physical resource of someone else to obtain data/information, in a way it was not intended to be used.
The purpose of the site would mostly be to serve information to its users 1 page at a time with the frequency of the next page being comparable to your average human reading speed and the size of the page.
But, in the case of scraping we can request all the pages of the specific site at the same time or within milli-seconds or seconds apart, which can place an unusual burden on the physical resources of the site, which in turn will lead to poor performance for normal users seeking a response from a website to use it for its intended purpose.
Another problem that arise from web scraping is, understanding for what purpose the scraped data is planned to be used for. If the data will be used in a way that would bring forth economic benefit to the web scraper, it is also within breach of copyright laws, as the website being scraped is the author and therefore the data/information of that site can be considered the intellectual property of that website.
So are you allowed to scrape website:
Yes, if you have checked the following boxes:
- Does the website offer an API to obtain data?
- Does the terms and conditions of the website allow for scraping? You will see any of the following jargon being used in T&Cs to describe this restriction: crawling, scraping, harvesting or automated uses
- Are you going to use the data for commercial use?
- Abide by the rules of the robot.txt file
- You will abide to fair use of someone else’s resources. Insert a timer to throttle the interval of requests made to a website. Search the robot.txt for a crawl-delay setting; if there’s none, use a conservative crawl rate 1 request every 10 - 15 seconds
- Identify your web scraper with a legitimate user agent string.
If you are in doubt on the legality of what you’re doing, don’t do it
The following arguments have already been proven to be invalid to justify your actions benbernardblog:
- “I can do whatever I want with publicly accessible data.” False - The problem is that the “creative arrangement” of data can be copyrighted.
- “This is fair use!” This is a grey area, what you consider as fair use might not always be considered as fair use when objectively judged. Cases: Kelly v. Arriba Soft Corp., Associated Press v. Meltwater U.S. Holdings, Inc
- “It’s the same as what my browser already does! Scraping a site is not technically different from using a web browser. I could gather data manually, anyway!” False - If the Terms & Conditions Service (T&C’s) often contain clauses that prohibit crawling/scraping/harvesting and automated uses of their associated services. You’re legally bound by those terms and accept them when accessing the website.
- “The worse that might happen if I break their Terms & Conditions Service is that I might get banned or blocked.” This is a grey area, in some cases a website might block your IP to their site (permanently/temporary), or your account can be locked, or legal action can be taken against. Cases: Facebook v. Pete Warden, LinkedIn Corporation v. Michael George Keating, LinkedIn Corporation v. Robocog Inc
- “This is completely unfair! Google has been crawling/scraping the whole web since forever!” True - But law has apparently nothing to do with fairness. It’s based on rules, interpreted by people. Also, most websites want Google to scrape their sites and will not seek legal action against Google, also Google makes use of fair use policies and abide by the robot.txt rules laid out by each site.
- “But I used an automated script, so I didn’t enter into any contract with the website.” & “Terms & Conditions (T&C’s) are not enforceable anyway. They have no legal value.” False - _As is the general rule with any contract, a website’s terms of use will generally be deemed enforceable if mutually agreed to by the parties. […] Regardless of whether a website’s terms of use are clickwrap or browse wrap, the defendant’s failure to read those terms is generally found irrelevant to the enforceability of its terms. One court disregarded argument that awareness of a website’s terms of use could not be imputed to a party who accessed that website using a web crawling or scraping tool that is unable to detect, let alone agree, to such terms. Similarly, one court imputed knowledge of a website’s terms of use to a defendant who had repeatedly accessed that website using such tools. Nevertheless, these cases are, again, intensely factually driven, and courts have also declined to enforce terms of use where a plaintiff has failed to sufficiently establish that the defendant knew or should have known of those terms (e.g., because the terms are inconspicuous), even where the defendant repeatedly accessed a website using web crawling and scraping tools. _ - Bingham McCutchen LLP law firm. Cases: Internet Archive v. Suzanne Shell, Southwest Airlines Co. v. BoardFirst, LLC
- “I respected their robots.txt and I crawled at a reasonable speed, so I can’t possibly get into trouble, right?” This is a grey area, robots.txt is recognized as a “technological tool to deter unwanted crawling or scraping”. But whether you respect it, you’re still bound to the Terms & Conditions (T&C’s).
- “Okay, but this is for personal use. For my personal research only. I won’t re-publish it, or publish any derivative dataset, or even sell it. So, I’m good to go, right?” This is a grey area, Terms & Conditions (T&C’s) often prohibit automatic data collection, for any purpose
- “But the website has no robots.txt. So, I can do what I want, right?” False - You’re still bound to the Terms & Conditions (T&C’s), and the content is copyrighted.
Basic HTML
Ok so once we passed the legal, ethical a moral question about web scraping, we can start by getting into web scraping.
One of the most important things to understand when doing web scraping is to understand how websites are displayed. Understanding how your web browser interprets and displays a web pages to you is critical when trying to extract data from that page.
So, web browsers such as Chrome, IE, Safari etc. Is a desktop application that can make requests to a specific web address known as a URL(Uniform Resource Locator) and will then expect a response back from that specific URL? A browser can handle multiple response formats, but the most common format that would be expected is HTML (HyperText Markup Language).
HTML can be considered as the building blocks of the world wide web (www). HTML is a structured language used to describe the structure and layout of a webpage, which is what the Mark Up (ML) in HTML refers to. The HyperText component refers to the ability of HTML to link to other HTML pages on the web. These links are what gives us the world wide web as we know it today.
Tags
HTML makes use of markup notations within regular text which then describes how a web pages needs to be structured and laid out. HTML makes use of tags to describe the mark up that needs to be applied by the browser to display the content.
Most tags require an open and closing tags, some tags only require an opening tag. Tags contain an element name which are then surrounded by “<” “>”. An open tag does not contain a forward slash, where a closing tag does contain a forward slash.
The text contained between 2 tags will then be the text that is displayed to the user with the browser. The tags will not be displayed but will only affect how the text between the tags should be displayed. Ex.
<element>Text to display here</element>
The element name inside the tag is case insensitive and can contain the following names:
- head
- title
- body
- header
- footer
- h1
- p
- table
- div
- span
- nav
- ul
- ol
- li
This is not all the tags available in HTML, but the commonly used once. During this tutorial we will only be using a few of them
If you quickly want to see how this page is laid out in html, hit F12 within your browser and you will be able to see the HTML of this page
Basic Layout
The basic layout of an HTML page will be as follow:
<!DOCTYPE html>
<html>
<head>
<title>Home</title>
</head>
<body>
<nav>
<ul>
<li>Home</li>
<li>About us</li>
<li>Contact us</li>
</ul>
</nav>
<h1>My First Web scraper</h1>
<p>Hello world</p>
<img>
<body>
<footer>
<p>All rights reserved</p>
</footer>
</html>
This is the basic syntax of an HTML webpage. Tags are wrapped inside one another to provide the required structure:
- HTML documents must start with a type declaration - !DOCTYPE html
- The HTML document is contained between html tags.
- The meta and script declaration of the HTML document is between the head tags. 1.1. The title tag defines the title of the page and will be displayed as the tab name in the browser.
- The visible part of the HTML document is between the body tags. 1.1. Firstly, we will define a navigation bar with the nav tag. 1.1. The navigation bar then consists of an ul unordered list tag. 1.1. The li list items will act as buttons on the navigation bar to different pages on this web site
- Title headings are defined with the h1 through h6 tags, which act as predefined styles for headings.
- Paragraphs are defined with the p tag.
- Images are defined with the img tag.
- Anything that should appear at the bottom of the screen will be placed in the footer tag
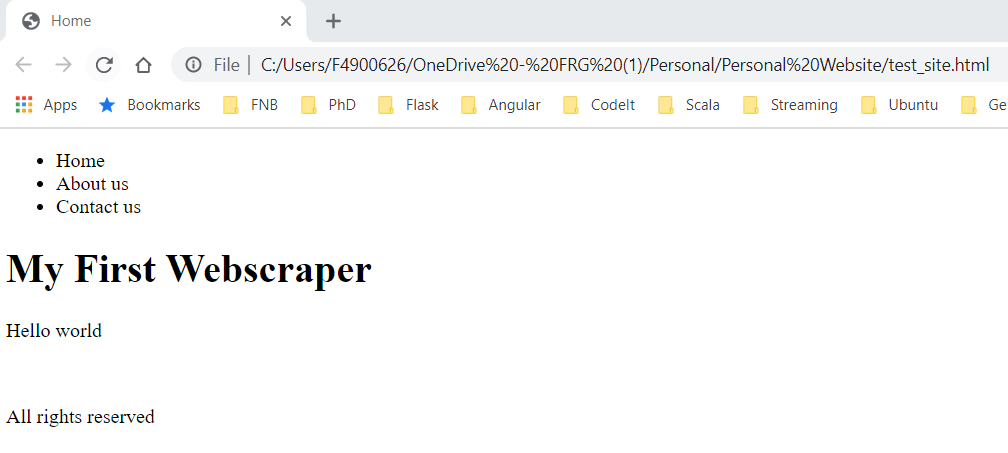
This might not be what you expected, but we have not assigned any styling to this basic HTML structure. That is where CSS comes into play, which we will not be discussing during this tutorial.
HTML is the structure of the page layout, where CSS is the styling/decorations on top of the structure and JavaScript produces events and actions for the web page
Attributes
Each tag can then also contain additional attributes. These attributes will help a lot in identifying the data we want to extract later. Attributes provide additional information about the element and they are always contained within the start tag
<a href="https://www.w3schools.com"><img src="img_girl.jpg" width="500" height="600"></a>
The a tag contains an attribute which specifies a link to another web page. The image tag is wrapped inside the a tag which contains an attribute regarding how the width and height of the image needs to be rendered and it specifies the source from where the image should be loaded from. This line will generate the “img_girl.jpeg” image, display it with a resolution of 500x600 and the entire image will be a link to “https://www.w3schools.com” if clicked on.
When it comes to web scraping the most important attributes we will be looking at will be the class and id attributes. These attributes are used to uniquely identify a single tag, like in the case of “id” only 1 tag on the entire html page can have a specific id. Where class is used to uniquely identify multiple tags or a group of tags. These tags play a critical role also in applying CSS(Cascading Style Sheet) and JavaScript to the HTML page when loading.
The below resources helped me a lot to get going with basic web design:
BeautifulSoup
Beautiful Soup is a Python library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the HTML structure of a web page.
We will need to download the BeautifulSoup package first:
pip install beautifulsoup4
I prefer using the lxml parser to parse the HTML page into BeautifulSoup
pip install lxml
If you don’t want to use lxml, the standard HTML parser should be available on your computer already
How to approach scraping
Before we start writing our code, we need to understand what it is that we want to scrape and from where we are going to scrape it from. So first we need to inspect the targeted website.
In our case we want to scrape a list of all the GDP figures of all countries. So, we know if will most likely be in a table format and therefore we already know we are going to look for the <table> tag. We now just need to figure out how we are going to identify the exact table we are looking for, because there might be multiple table on this specific web page. We are going to use this link to Wikipedia https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal). Paste this link into your favourite browser, let the page load. You can either hit the F12 button directly which will open the html source file for you from the top. Or, you can navigate to the data you are looking for in your browser, right click on it and select “Inspect” (If you are using Chrome). In our case I have scrolled down until I saw a table listing all the countries by GDP, I then right clicked on the heading of table “Per the International Monetary Fund (2019 estimates)”.
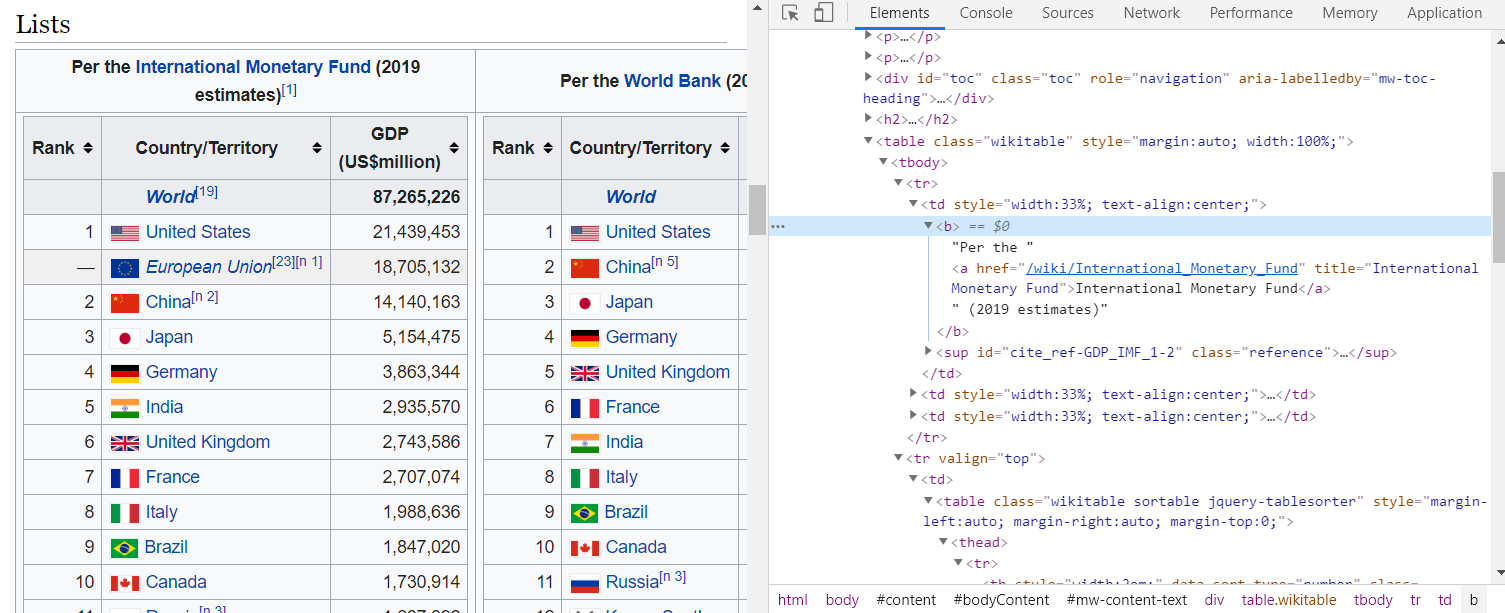
We can see that the heading we clicked on is wrapped in side a <table> tag. The heading is also wrapped within a <tbody> table body tag within a <tr> table row tag inside a <td> table data tag. These tags are important to consider as it will help us to extract the data we need. The next <tr> tag contains a <td> tags which then again contains a <table> tag, what to do now? In this unique case we see 3 tables built inside 1 table, therefore it appears as 3 lists being compared side by side. In this case it is nice as it displays the GDP rankings according to 3 different sources. So, as we scroll down during this inspection we will see 3 more tables listed inside <td> tags of the original <table> tag we selected when we inspected the title/heading of the table.
So, the first thing that we would want to identify, is a unique identifier, something that can uniquely identify each table. But, again another curve ball has been thrown our way, as none of the table have the id attribute. All of them only contain the class attribute, and yet another curve ball, as all of them have the same class attribute = “wikitable”.
So, what to do in this case, this is where the full power of Beautiful Soap comes out and will really help us overcome this challenge.
We will use BeautifulSoup to extract a list of all the table tags with this class “wikitable”. BeautifulSoup will build up a list of each tag matching the criteria with all the tags contained inside it. This gives us an opportunity to loop through the list and only get the tables that match the headers we know will be in our dataset we are looking to scrape like “Rank”, “Country/Territory” and “GDP”.
Once we identified the table we are looking for we will then loop through that table and extract all the text from the <td> tag inside, the <tr> tag, inside the <tbody> tag inside the <table> tag we got from the table list generated by BeautifulSoup
How to use BeautifulSoup to scrape a website
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from bs4 import BeautifulSoup
import requests
req = requests.get("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)",headers={'user-agent':'lambrie.github.io/2020-04-16-scrape-data-from-a-website'})
# Best practise for ethical scraping to include user-agent with a link to a site explain why we accessed this page through a scraper
soup = BeautifulSoup(req.content, 'lxml')
# Other parsers: 'html.parser', 'xml'
tables = soup.find_all("table", class_="wikitable")
# Alternative: tables = soup.find_all("table", {class:"wikitable"})
for table in tables: # Iterate over each table
headers = table.find_all("th") # Obtain all header tags in this table
try:
if len(headers) == 3:
headers = [head.text.replace("\n","") for head in headers] # List comprehension
if 'Rank' in headers[0] and 'Country' in headers[1] and 'GDP' in headers[2]:
tableData = f"{headers[0]}|{headers[1]}|{headers[2]}\n" # Set the headers to be printed out first, before adding the data from the table
for tr in table.find_all("tr"):
rowValue = "" # Reset the row value on each row iteration
for td in tr.find_all("td"):
rowValue += "{}|".format(td.text.replace('\n','').replace(',',''))
# Add row data from td tag
if rowValue: tableData += f"{rowValue} \n" # If a blank line, don't include in the output
print(tableData) # Print the result
break # Break the loop, as we are only looking for the first table
else:
continue # Continue with the loop to check all tables that only contain 3 headers
except IndexError:
continue # Error handling in case index don't align
else:
print("Table not found") # If the break is removed from the loop, then the else should be removed.
Firstly, we need to import all the modules we will require to scrape this Wikipedia page. We are importing the requests module to make an http request to a website and return its contents. The requests module will act like our browser in this case.
Once a response was received from the website, we will parse the html page into BeautifulSoup format so we can use the BeautifulSoup object to work on.
We will then use the find_all function from BeautifulSoup to identify all tables with the class name we identified. There we are performing a search of all <table> tags within the HTML page with a class type of “wikitable”.
So, we know there are going to be 4 tables matching our criteria, because there are 4 <table> tags with the above class name. The 3 visible tables are inside a table, therefore 4. Our aim is to get the first table in the main table, according to the index of the list of tables we know it will be the table in position 1 of tables list variable.
We will then perform a loop over the list of all table’s tags identified.
At line So we will convert the BeautifulSoup headers list to a list of strings, where we remove line breaks. This is something that will impact the way we display the results only and will not really be necessary, but for the purpose of this tutorial, we will include it to get beautiful output at the end. So, we know we will identify our table based on the headers of the table. So firstly, we know a table can have headers, which will have the tag <th>. Then we know it must have only 3 headers and that the header must contain “Rank”, “Country” and “GDP” in this exact order. If the table complies with these header criteria we can easily continue looking at the content of this table in the loop.
We will then be looking at all <tr> tags, which represents a single row in table. We know the <tr> tag can contain table header <th> tags or table data <td> tags. We are only interested in the <td> tags because we already identified all the header <th> tags. We then build up the row information with a | separator, so that we can easily write the results to a csv file as we iterate over each <td> tag within the <tr> tag.
After we iterated over each <td> tag we need to return the result to the tableData variable which will build up our result, therefore we only want to commit table row <tr> tags with table data <td> tags that are not empty.
Once we built up our tableData variable and we have finished the iteration, we will break out of the table loop. Because we know we are looking for the first valid table we can break out of the loop.
The output for this will then be as follow:
Rank|Country/Territory|GDP(US$million)
1| United States|21439453|
—| European Union[23][n 1]|18705132|
2| China[n 2]|14140163|
3| Japan|5154475|
4| Germany|3863344|
5| India|2935570|
6| United Kingdom|2743586|
7| France|2707074|
8| Italy|1988636|
9| Brazil|1847020|
10| Canada|1730914|
11| Russia[n 3]|1637892|
12| Korea South|1629532|
13| Spain|1397870|
14| Australia|1376255|
15| Mexico|1274175|
16| Indonesia|1111713|
17| Netherlands|902355|
18| Saudi Arabia|779289|
19| Turkey|743708|
20| Switzerland|715360|
— | Taiwan|586104|
21| Poland|565854|
22| Thailand|529177|
23| Sweden|528929|
24| Belgium|517609|
25| Iran|458500|
26| Austria|447718|
27| Nigeria|446543|
28| Argentina|445469|
29| Norway|417627|
30| United Arab Emirates|405771|
31| Israel|387717|
32| Ireland|384940|
—| Hong Kong|372989|
33| Malaysia|365303|
34| Singapore|362818|
35| South Africa|358839|
36| Philippines|356814|
37| Denmark|347176|
38| Colombia|327895|
39| Bangladesh|317465|
40| Egypt|302256|
41| Chile|294237|
42| Pakistan|284214|
43| Finland|269654|
44| Vietnam|261637|
45| Czech Republic|246953|
46| Romania|243698|
47| Portugal|236408|
48| Peru|228989|
49| Iraq|224462|
50| Greece|214012|
51| New Zealand|204671|
52| Qatar|191849|
53| Algeria|172781|
54| Hungary|170407|
55| Kazakhstan|170326|
56| Ukraine|150401|
57| Kuwait|137591|
58| Morocco|119040|
59| Ecuador|107914|
60| Slovakia|106552|
—| Puerto Rico|99913|
61| Kenya|98607|
62| Angola|91527|
63| Ethiopia|91166|
64| Dominican Republic|89475|
65| Sri Lanka|86566|
66| Guatemala|81318|
67| Oman|76609|
68| Venezuela|70140|
69| Luxembourg|69453|
70| Panama|68536|
71| Ghana|67077|
72| Bulgaria|66250|
73| Myanmar|65994|
74| Tanzania|62224|
75| Belarus|62572|
76| Costa Rica|61021|
77| Croatia|60702|
78| Uzbekistan|60490|
79| Syria[n 4]|60043/Na|
80| Uruguay|59918|
81| Lebanon|58565|
—| Macau|55136|
82| Slovenia|54154|
83| Lithuania|53641|
84| Serbia|51523|
85| Congo Democratic Republic of the|48994|
86| Azerbaijan|47171|
87| Turkmenistan|46674|
88| Côte d'Ivoire|44439|
89| Jordan|44172|
90| Bolivia|42401|
91| Paraguay|40714|
92| Tunisia|38732|
93| Cameroon|38632|
94| Bahrain|38184|
95| Latvia|35045|
96| Libya|33018|
97| Estonia|31038|
98| Sudan|30873|
99| Uganda|30666|
100| Yemen|29855|
101| Nepal|29813|
102| El Salvador|26871|
103| Cambodia|26730|
104| Honduras|24449|
105| Cyprus|24280|
106| Zambia|23946|
107| Senegal|23940|
108| Iceland|23918|
109| Papua New Guinea|23587|
110| Trinidad and Tobago|22607|
111| Bosnia and Herzegovina|20106|
112| Laos|19127|
113| Afghanistan|18734|
114| Botswana|18690|
115| Mali|17647|
117| Gabon|16877|
116| Georgia|15925|
118| Jamaica|15702|
119| Albania|15418|
120| Mozambique|15093|
121| Malta|14859|
122| Burkina Faso|14593|
123| Mauritius|14391|
124| Benin|14374|
125| Namibia|14368|
126| Mongolia|13637|
127| Armenia|13444|
128| Guinea|13368|
129| Zimbabwe|12818|
130| North Macedonia|12672|
131| Bahamas The|12664|
132| Madagascar|12550|
133| Nicaragua|12528|
134| Brunei|12455|
135| Equatorial Guinea|12142|
136| Moldova|11688|
137| Congo Republic of the|11576|
138| Chad|11026|
139| Rwanda|10209|
140| Niger|9443|
141| Haiti|8819|
142| Kyrgyzstan|8261|
143| Tajikistan|8152|
—| Kosovo|7996|
144| Malawi|7522|
145| Maldives|5786|
146| Togo|5502|
147| Mauritania|5651|
148| Montenegro|5424|
149| Fiji|5708|
150| Barbados|5189|
151| Somalia|4958|
152| Eswatini|4657|
153| Sierra Leone|4229|
154| Guyana|4121|
155| Suriname|3774|
156| South Sudan|3681|
157| Burundi|3573|
158| Liberia|3221|
159| Djibouti|3166|
160| Timor-Leste|2938|
—| Aruba|2903|
161| Bhutan|2842|
162| Lesotho|2741|
163| Central African Republic|2321|
164| Eritrea|2110|
165| Belize|2001|
166| St. Lucia|1992|
167| Gambia|1773|
168| Antigua and Barbuda|1688|
169| Seychelles|1644|
170| San Marino|1591|
171| Solomon Islands|1440|
172| Grenada|1238|
173| Comoros|1179|
174| St. Kitts and Nevis|1032|
175| Vanuatu|951|
176| Samoa|905|
177| St. Vincent and the Grenadines|856|
178| Dominica|593|
179| Tonga|488|
180| São Tomé and Príncipe|430|
181| Micronesia Federated States of|381|
182| Palau|291|
183| Marshall Islands|220|
184| Kiribati|184|
185| Nauru|108|
186| Tuvalu|42|
Process finished with exit code 0